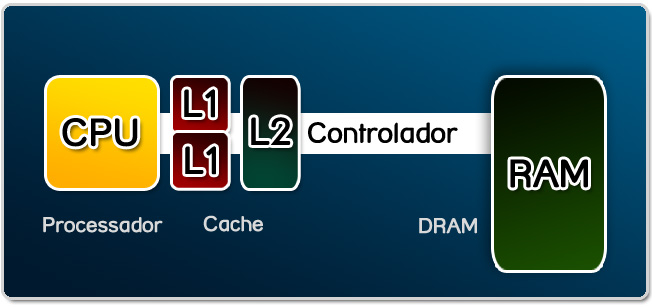
A memória cache é um tipo de extensão da memória RAM, atribuindo a ela dados recentemente acessados na RAM, afim de diminuir o tempo de busca de dados/registros durante alguma execução, ou seja, sempre que um dado é lido na memória, ele é inserido no cahce em seguida, pois assim, se necessária a leitura do mesmo dado novamente, não será necessário ir até a memória (mais longe), pois estará na cache (mais perto).
É então, calculado quantos acessos a execução teve na memória RAM e cache, onde o primeiro acesso é realizado, por ser na memória RAM, é chamado de miss cache (acesso fora da cache). Quando é um acesso na cache, esse é chamado de hit cahce (acesso dentro da cache). Imagine por exemplo que um looping for fará com que incremente +1 no valor de X, logo, no primeiro acesso a X, será realizado um miss cache, pois ainda não se encontra em cache (ou seja, até que X = 1, será miss cache). Porém a partir do segundo acesso, será realizado um hit cache, pois agora o endereço de X já está alocado no cahce.
Ou seja, se for um looping de 5 repetições, ocorrerá 1 miss cache (X = 1) e 4 hit cahce (X = [2,3,4,5]).
OBS: É viável saber que o tempo de acesso na memória cache é menor do que o tempo de acesso a RAM, gerando um conceito de localidade espacial e temporal.
Se uma informação é acessada dentro de um programa, é possível que informações adjacentes serão acessadas em um futuro próximo, ou seja, toda instrução ou comando que sucede outro, é considerado espacial.
X = 0
Y = 1 ---> Y é espacial por X
Z = 2 ---> Z é espacial por Y
Se uma informação é acessada dentro de um programa, é provável que ele seja acessado novamente em um futuro próximo, ou seja, toda intrução que é acessada repetidamente, é considerada temporal (como um looping por exemplo).
while (X != 5)
X = X+1; -----> X será acessado 5 vezes, logo é temporal.
Quando o precessador faz um acesso a um registro na memória é primeiro verificado se tal dado reside em seus dados, afirmando o conceito de que todo e qualquer acesso por instrução passa primeiramente pelo cache e depois pela RAM.
Este é o cálculo de tempo que toda uma instrução leva por acessos a memória, onde se o acesso a uma instrução de busca na memória leva 50 nanosegundos (hipoteticamente), o tempo total de acesso, considerando um looping de 50 acessos, será de:
TTA.M = acessos x tempo
TTA.M = 50 x 50
TTA.M = 2500 nanosegundos
Se considerarmoso tempo de acesso a um dado no cache igual a 3 nanosegundos e o tempo de acesso a um dado na memória principal igual a 50 nanosegundos, considerando um looping de 50 acessos, tem-se que o tempo é:
TTA.C = (Hits x tempo cache) + (Miss x tempo RAM)
TTA.C = (49 x 3) + (1 x 50)
TTA.C = 197 nanosegundos
O tempo médio de acesso em uma hierarquia de memória determina o tempo de acesso por instrução em função das probabilidades de acertos e erros de acessos e dos tempos desses acessos conforme a fórmula:
TMA = (ph x th) + (ph x tm)
onde,
TMA = Tempo médio de acesso
ph = Probabilidade de hit
th = Tempo em caso de hit
pm = Probabilidade de miss
tm = Tempo em caso de miss
Por exemplo: Um programa realiza 1000 acessos à memória durante a seua exwecução, e desses acessos, 20 são miss cahce. O tempo de acesso à cache é igual a 5 nanosegundos enquanto a memória principal é de 70 nanosegundos. Qual o tempo total de acessos e o tempo médio de acesso:
1 - TTA.M = 20 x 70 = 1400 nanosegundos
Como são 1000 acessos com 20 miss, então 980 são hit
2 - TTA.C = (980 x 5) + (20 x 70) = 4900 + 1400 = 6300 nanosegunos
3 - TMA = (ph x th) + (ph x tm)
TMA = Tempo médio de acesso
ph = 20/1000 = 0,02
th = 5
pm = 70
tm = 1 - PM = 1 - 0,02 = 0,98
TMA = (0,02 x 5) + (0,98 x 70) = 0,01 + 68,6 = 68,61
Uma memória principal possui uma certa quantidade de N bytes (endereços), dando a ela uma quantidade de X bits (por endereço), o qual é obtido através do cálculo de log de N (na base 2) = X, por exemplo:
2 bytes de memória
log 2 = X
2^X = 2
X = 1
------------
| end. 0 | -> Byte 0
------------
| end. 1 | -> Byte 1
------------
16 bytes de memória
log 16 = X
2^X = 16
X = 4
------------
| end. 0000 | -> Byte 0
------------
| end. 0001 | -> Byte 1
------------
| end. 0010 | -> Byte 2
------------
| end. 0011 | -> Byte 3
------------
| end. 0100 | -> Byte 4
------------
| end. 0101 | -> Byte 5
------------
| end. 0110 | -> Byte 6
------------
| end. 0111 | -> Byte 7
------------
.
.
.
------------
| end. 1111 | -> Byte 15
------------
Diante disso, é possível obter a quantidade de blocos da memória e a quantidade de linhas (end) por bloco. No caso de uma memória de 16 bytes, ela possui então 8 blocos com 2 endereços cada
------------
| end. 0000 | -> Byte 0
------------ ----> Bloco 1
| end. 0001 | -> Byte 1
------------
------------
| end. 0010 | -> Byte 2
------------ ----> Bloco 2
| end. 0011 | -> Byte 3
------------
.
.
.
------------
| end. 1110 | -> Byte 14
------------ ----> Bloco 8
| end. 1111 | -> Byte 15
------------
Na cache, cada bloco terá a mesma qunatidade de endereços dos blocos de memória, possuindo apenas a metade dos bits:
*CACHE
----------- -----------
00 | end. A1 | end. A2 | ---> Bloco 1
----------- -----------
01 | end. B1 | end. B2 | ---> Bloco 2
----------- -----------
10 | end. C1 | end. C2 | ---> Bloco 3
----------- -----------
11 | end. D1 | end. D2 | ---> Bloco 4
----------- -----------
|
V
Linhas
Como cada bloco têm 2 endereços, então o bit menos significativo do endereço indica a posição dentro do bloco, chamado de campo w, por exemplo:
000|0| -> Campo W
000|1| -> campo w
Os três outros bits que sobram em cada endereço, identificam o bloco na memória principal, por exemplo:
|000|0 -> Bloco 000
|001|0 -> Bloco 001
|000|1 -> Bloco 000
| |
| V
| End. no bloco (como um índice) ou campo w
|
V
ID Bloco
Para identificar o dado a ser colocado na cahce, é lido o bloco e seu índice dentro do bloco que residem na memória, por exemplo:
O dado com o endereço 0011 se encontra nos:
Bloco: 001
índice: 1
Na execução de um comando, alguns passos são definidos:
e2 = e2 + a1
Diante disso, o armazenamento da memória para a cache pode ser feita de 3 tipos, sendo eles:
Este método tem como característica a capacidade de inserir dados da memória no cache em qualquer uma das linhas, independete do dado ou de seu bloco.
Como o primeiro passo não está em cache, o passo é miss, precisando ser localizado na memória principal.
*Memória
------------
| end. 0000 | (a1)
------------ ----> Bloco A
| end. 0001 | (a2)
------------
.
.
.
------------
| end. 0100 | (c1)
------------ ----> Bloco C
| end. 0101 | (c2)
------------
.
.
.
------------
| end. 1000 | (e1)
------------ ----> Bloco E
| end. 1001 | (e2)
------------
e2 = 1001 (bloco E)
Todos os dados que lidos na memória, são posteriormente, armazenados em cache:
*Cache
--- --- --------- ------ ------
| 0 | 1 | | 100 | 00 | e1 | e2 |
--- --- --------- ------ ------
| 0 | 0 | | | 01 | | |
--- --- --------- ------ ------
| 0 | 0 | | | 10 | | |
--- --- --------- ------ ------
| 0 | 0 | | | 11 | | |
--- --- --------- ------ ------
| | | | |
| | v | |
| V Bloco | V
| ID de NULL | Dados
| V
V Linha
ID de mudança
Ou seja, o bloco E (100) é armazenado com todos os seus dados na linha 00, completando o passo 1
O procedimeno é extremamente o mesmo, como é a primeira leitura para "a1", ele não se encontra na cache, gerando um miss, precisando buscar na memória e alocar na cache:
a1 = 0000 (bloco A)
*Cache
--- --- --------- ------ ------
| 0 | 1 | | 100 | 00 | e1 | e2 |
--- --- --------- ------ ------
| 0 | 1 | | 000 | 01 | a1 | a2 |
--- --- --------- ------ ------
| 0 | 0 | | | 10 | | |
--- --- --------- ------ ------
| 0 | 0 | | | 11 | | |
--- --- --------- ------ ------
Armazenando o Bloco A (000) e todos os seus dados na linha 01
Como o procedimento lê elementos que já se encontram na cache, este é um hit, não realizando nada mais na cache (soma não é realizada pela cache).
Como este procedimento aloca o valor da soma em e2 e e2 já se encontra em cache, é um hit. Porém, já possui um valor e precisa ser alterado
*Cache
--- --- --------- ------ ------
| 1 | 1 | | 100 | 00 | e1 | e2 |
--- --- --------- ------ ------
| 0 | 1 | | 000 | 01 | a1 | a2 |
--- --- --------- ------ ------
| 0 | 0 | | | 10 | | |
--- --- --------- ------ ------
| 0 | 0 | | | 11 | | |
--- --- --------- ------ ------
|
V
ID de modificação alterado
Os procedimentos são semelhantes, porém, com o método de mapeamento direto, cada bloco será armazenado em uma linha específica. A identificação para qual linha cada bloco vai, é dada pelos número centrais do endereço, por exemplo:
e2 = 1|00|1
Logo, este endereço é dos:
Bloco: 100
Linha: 00
índice: 1
O processo é exatamente o mesmo do anterior, como se encontra em memória, é realizado um miss e depois inserido na cache:
*Cache
--- --- --------- ------ ------
| 0 | 1 | | 1 | 00 | e1 | e2 |
--- --- --------- ------ ------
| 0 | 0 | | | 01 | | |
--- --- --------- ------ ------
| 0 | 0 | | | 10 | | |
--- --- --------- ------ ------
| 0 | 0 | | | 11 | | |
--- --- --------- ------ ------
Perceba que no método anterior 3 bits eram alocados para identificação do bloco, mas agora como 2 deles são para identificar
a linha de alocação, apenas 1 foi armazenado para o bloco
É neste passo que a principal diferença é mostrada, pois deverá sacontecer uma sobreposição
a1 = 0000
Perceba que a ID de linha é igual a de e2, que já está alocado na linha 00 do cache
*Cache
--- --- --------- ------ ------
| 0 | 1 | | 1 | 00 | e1 | e2 |
--- --- --------- ------ ------
| 0 | 0 | | | 01 | | |
--- --- --------- ------ ------
| 0 | 0 | | | 10 | | |
--- --- --------- ------ ------
| 0 | 0 | | | 11 | | |
--- --- --------- ------ ------
Então, a localização de a1 deverá ser armazenada no lugar de e2, ou seja, susbtituir a posição de e1
*Cache
--- --- --------- ------ ------
| 0 | 1 | | 0 | 00 | a1 | a2 |
--- --- --------- ------ ------
| 0 | 0 | | | 01 | | |
--- --- --------- ------ ------
| 0 | 0 | | | 10 | | |
--- --- --------- ------ ------
| 0 | 0 | | | 11 | | |
--- --- --------- ------ ------
Os demais passos são iguais aos do procedimento anterior.
Este procedimento irá separar as linhas do cache em blocos de 0 até n-1, com 2 linhas cada:
*Cache
--- --- --------- ------ ------
| 0 | 0 | | | 00 | | |
--- --- --------- ------ ------ ----> Conjunto 0
| 0 | 0 | | | 01 | | |
--- --- --------- ------ ------
--- --- --------- ------ ------
| 0 | 0 | | | 10 | | |
--- --- --------- ------ ------ -----> Conjunto 1
| 0 | 0 | | | 11 | | |
--- --- --------- ------ ------
Para identificar em qual conjunto o dado será armazenado no cache, basta ver o bit após o menos significativo, por exemplo:
10|1|1 -> Bit menos significativo
|
V
Conjunto